曾 亮
湖北省荆州电力局,湖北 荆州 434001
在一定的规划期内,电力系统的负荷水平决定了电力系统发展的规模与速度。因此,中长期负荷预测的结果在一定程度决定了未来规划期内电力系统的发展。当前电力市场由卖方市场转向买方市场,过去的以产定销变成了现在的以销定产,生产计划和基建计划的安排都对中长期电力负荷预测提出更高的要求。中长期负荷预测中尤以用电量预测为重要,故本文只对用电量预测的方法进行专门研究。
1 中长期用电量预测方法的局限
中长期用电量预测方法主要分为定量和定性两大类。定性的方法主要有类比法和专家估算法等。定量的方法主要有回归分析法、指数平滑法、成长曲线法和灰色模型法等。
许多研究工作者现在已经认识到单独地使用定性或定量的方法进行中长期用电量预测都是不够的。电力工业的发展是一个非常复杂的动态大系统,其中有许多社会性的、政策性的、人的心理行为的、技术性的等等不确定性的随机因素。对于这样一个关联于社会、经济、技术、环境的复杂动态大系统,企图仅凭现有的数学知识来建立精确的数学模型以进行定量分析是不够的,同样单纯地依靠经验知识进行定性分析也是不够的。唯一的解决方法就是将定性分析和定量分析有机地结合起来,辩证地统一。
2 负荷预测的新思路
传统的定量方法往往是直接去建立用电量与时间或其它因素间的函数关系式。这样会使得预测结果的可信度较低,而且面对相当多的不确定信息也无能为力。因此,必须离开以方程为中心的传统思维定式,去研究各种非方程的预测方法。
有经验的预测工作者是如何成功地进行预测的呢?可以设想他们有意无意地将预测的历史数据和相关因素的历史数据在头脑中进行归纳整理,运用其专业知识与过去成功和失败的经验教训,将那些数据分成若干类。进行预测时,他们把收集到的相关因素的具体状态值与历史数据类的状态值进行对比,寻找与这组状态值最接近的一个历史数据类,再根据该类的预测量的特征作出初步预测。然后他们根据相关因素的具体状态值与历史数据类的不同,作出相应修正,得到预测值。
基于以上的思路,利用模糊数学理论,提出一数学模型模拟此预测过程,把专家在预测中无法直接说明的直觉和经验通过模拟他们的预测过程间接地加以考虑,从而解决不确定的定性因素的处理。下面简述一下数学模型的原理,整个模型分为6部分。
2.1 因素显著性分析
设y为被预测的变量,本文的y为用电量的年增长率,Y为y的所有可能值构成的集合。
首先运用专家调查法,或集值统计法,或层次分析法初步选出y的相关因素。设初选得到的因素为f1,f2,…,fn。本文的初选因素为GDP的年增长率、第一产业的GDP年增长率、第二产业的GDP年增长率、第三产业的GDP年增长率、第一产业的GDP比重、第二产业的GDP比重、第三产业的GDP比重、城镇人口比重、国民收入的年增长率、人口增长率等。考虑15年的历史数据(1978~1992年),即T=15。
Zt=(Xt,Yt)状态空间,用于表示系统环境
Xt=(Xt1,Xt2,…,Xtn),t=1,…,T
Yt是y在第t期的值,Xti是第t期因素fi的取值,i=1,…,n
检验每个fi影响y的显著性,有2种方法:
(1) 弹性法(本文推荐选用)
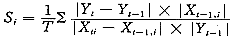
称Si为y对于fi的弹性水平,又取λ>0作为检验标准,若Si<λ,则认为fi对y在λ水平下影响不显著,可以将其从相关因素中略去。
(2) 速率法[1]
为简便计算,仍设最后选定的相关因素为f1,f2,…,fn。
2.2 数据预处理
数据的预处理有2种方法可供选用。
(1) 中心化标准化法[1]
(2) 极差化法(本文选用,因所得数据非负)
令:my=minyt, My=maxyt
mi=minxti, Mi=maxxti
对原数据作变换:
yt′=(yt-my)/(My-my)
Xti′=(xti-mi)/(Mi-mi)
i=1,…,n;t=1,…,T
为行文的方便,处理后的数据仍记为:
(Xt1,Xt2,…,Xtn,yt),t=1,…,T
2.3 因果聚类
(1) 样本的形成:对每个单位时段(如1年)构成一个样本,(Xt1,Xt2,…,Xtn)其中Xt表示第t个样本,Xti表示第t个样本第i个环境因素值。i=1,…,n,t=1,…,T
(2) 标定:即利用选定算法算出所有历史样本间的相关因子rij,从而构成模糊关系矩阵R。
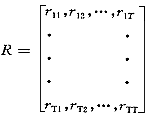
T为历史样本总数
本文采用的算法为指数指标法:
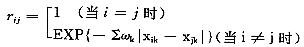
其中ωk是权系数,经专家咨询和测算得到。
求得R后,利用λ偏差度在选定区间[λ1,λ2]内选出最佳截水平λo,对R进行截处理,求得截矩阵Rλ。λ又称分类水平,λ的截处理即当rij≥λ时λij等于1,反之则为0。
(3) 动态聚类中截水平λ最佳值λo的选定。
采用λ的变化率ci作为λ的定量选择标准。
ci=(λi-1-λi)/(ni-ni-1)
其中 [1] [2] [3] [4] 下一页
|





 网友评论:(只显示最新10条。评论内容只代表网友观点,与本站立场无关!)
网友评论:(只显示最新10条。评论内容只代表网友观点,与本站立场无关!)