卫志农1, 张云岗1, 郑玉平2
1. 河海大学电气工程学院,江苏 南京210098;2.国电公司自动化研究院,江苏 南京210003
1 引言
不良数据的检测与辨识是电力系统状态估计中的重要问题,而不良数据的检测又是辨识的基础,被用于判断某次量测采样中是否存在不良数据。常用的方法包括目标函数J(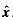 )检测、加权残差Rw检测或标准化残差Rn检测、量测量突变检测以及上述几种方法的综合使用。 )检测、加权残差Rw检测或标准化残差Rn检测、量测量突变检测以及上述几种方法的综合使用。
量测量突变检测方法利用了前一采样时刻的量测信息,能有效地克服残差污染和残差淹没现象。但是,该方法要求电力系统网络结构在两相邻采样间隔之间必须保持不变,而且采用假设检验的方法,必然存在误检或漏检的风险。
为了克服上述不足,本文利用模糊数学聚类分析方法,对量测量突变检测进行了改进。一方面,不再仅仅利用检测门槛值来判定不良数据,而是采用模糊数学中的隶属度概念,说明该量测以多大程度属于或不属于不良数据;另一方面,采用了迭代自组织数据分析技术ISODATA (Iterative Self-Organizing Data Analysis Technique A)[1],并对其进行了改进。文中采用了加权形式的ISODATA方法,对量测值进行了模糊聚类分析,从而改善了检测效果。
2 量测量突变检测原理
量测量突变检测方法的应用有个基本假定:
(1) 在相邻的两采样间隔间,电力系统的网络结构没有变化。
(2) 前一采样时刻的量测数据是可靠数据。
所谓突变检测,就是利用前一采样时刻的量测量与本采样时刻的量测量进行比较,如果某量测量有意外的突变,即被判为可疑数据而予以检测出。一般来说,要判定某一量测量是否突变,通常由某一采样时刻的实际量测量与前一时刻的量测量一步预测值之差是否超过某一门槛值而确定。
用量测量的一步预测增量或在正常量测条件下应有的量测增量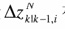 在某误检概率Pe下的值作为检测门槛值εi,这里,假定Pe=0.005。按通常的假设检验方法逐个地对量测数据进行检测时,对H0有 在某误检概率Pe下的值作为检测门槛值εi,这里,假定Pe=0.005。按通常的假设检验方法逐个地对量测数据进行检测时,对H0有
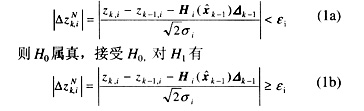
式中 zk,i为tk时刻的第i个实际量测值,(i=1,2, 3,…,m);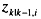 为基于tk-1时刻的第i个量测对时刻tk所作的一步预测值;εi为检测门槛值;△zk,i为第i个量测增量; 为基于tk-1时刻的第i个量测对时刻tk所作的一步预测值;εi为检测门槛值;△zk,i为第i个量测增量;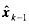 为tk-1时刻的n维状态矢量估计值;Zk-1,H()分别为tk-1时刻的m维量测矢量和m×n阶雅可比矩阵;△k-1为两采样间隔之间 为tk-1时刻的n维状态矢量估计值;Zk-1,H()分别为tk-1时刻的m维量测矢量和m×n阶雅可比矩阵;△k-1为两采样间隔之间
系统的非随机干扰矢量。
式(1)意味着,量测突变量的有名值超过4σi即被作为可疑数据而被检测出来。
3 改进的ISODATA法
3.1 模糊ISODATA聚类法的基本原理
在上述传统的量测量突变检测方法中,采用了假设检验方法,要根据一定的误检概率来确定门槛值,这就必然存在2个风险:误检和漏检,且一般误检概率和漏检概率是有矛盾的。误检概率越小,就意味着漏检概率越大,反之亦然。
为此,本文采用模糊聚类分析中的改进ISODATA方法把量测数据分为2类:良性数据和不良数据。首先利用常规量测量突变检测方法的检测结果,形成初始分类矩阵,然后用标准残差  与两相邻采样时刻的量测数据的差值DZ作为2个特征值,从而迭代求出在此初始条件下的最优分类结果。 与两相邻采样时刻的量测数据的差值DZ作为2个特征值,从而迭代求出在此初始条件下的最优分类结果。
聚类分析属于数理统计多元分析的一支[2]。设有限样本集


则式(6)、(7)为第i类的聚类中心。
要在划分空间Mc中找到最优的分类矩阵,在一个合理的分类中,就应使每一类中的元素与该类聚类中心的距离平方和尽可能地小,从而得到如下目标函数:
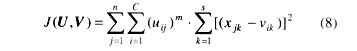
式中 m是为了加强uij属于各类从属程度的对比度而引入的参数[2],有一定的主观任意性。
实验结果表明,参数  采用2为最优。此目标函数的极小值是可求的,证明见文[3]。 采用2为最优。此目标函数的极小值是可求的,证明见文[3]。
3.2 对模糊ISODATA聚类法的改进
式(8)的目标函数并未考虑各个指标的不同权重对分类结果的影响,而实际上,它们的影响是不一样的。所以,上述的分类有可能导致分类的结果不合理。为此,将式(8)改进为
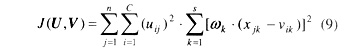
式中 ωk为第k个特征指标的权值。
式(9)的目标函数反映了所有待聚类元素与所属类聚类中心的加权广义欧氏权距离的平方和[4]。
式(9)中,特征指标权值wk的选择对式(9)的效果影响较大,应能较好地反映出该特征指标对目标函数的影响。所以,如果设S个特征指标的权向量为
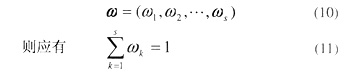
由此可见,隶属度函数表述的是该特征指标从属于某分类的程度,能满足上述要求,所以,ωk一般情况下采用隶属度,本文算例的仿真结果表明,该选择是切实可行的。
实际情况中,因各个特征指标对分类的影响不同,式(9)对各个指标采用了不同的权重,因而更符合实际情况。而传统的ISODATA法并未考虑指标权重对分类的影响,实质是将指标权重视为等权重,这就可能导致分类结果不准确甚至根本不可信。因此,改进的模糊ISODATA法在理论上更为严谨,聚类结果更贴近真实情况。
4 仿真算例及分析
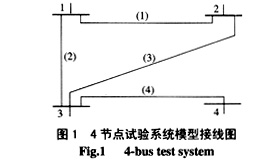
采用传统的4节点模型进行仿真,其接线图如图1所示。其量测配置如表1所示,量测总测点数为16。
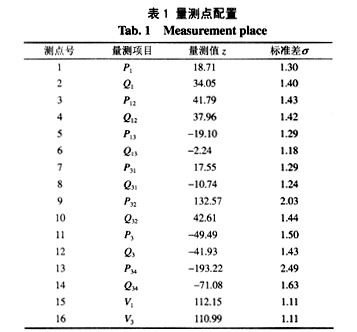
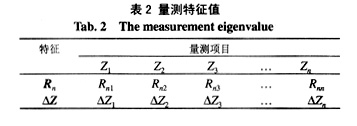
这里,采用功率量测的标准残差Rn和相邻采样时刻量测值之差DZ这2个特征值,即可得到样本数据集如表2所示。
采用传统的量测突变检测来形成初始分类矩阵U0。当本次采样时刻的量测量和前一时刻的量测量预测值之差大于某一门槛值时,对应量测取对于不良数据集合的隶属度UA(Zi)为任一个0.5和1之间的数,对于良数据集合的隶属度UB(Zi)为一个0和0.5之间的数,且满足UA(Zi)+ UB(Zi)=1。本文仿真中分别取为0.723和0.177。
得到初始分类矩阵U0后,即可进行迭代计算,求出不良数据集。具体步骤如下:
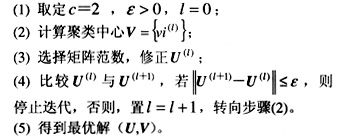
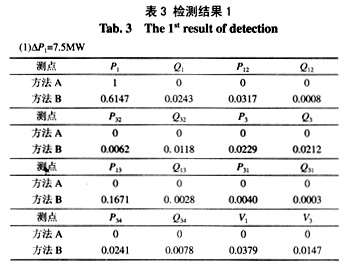
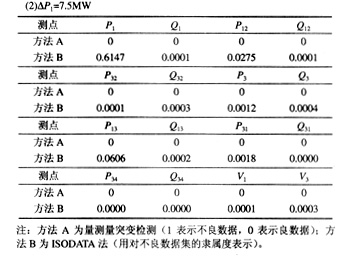
在P1点,先后两次设置相同的不良数据值DP1=7.5MW,并在其它量测点处设置服从N(0,1)正态分布的随机干扰,检测结果如表3所示。
在Q3点做相同的实验,设置不良数据值DQ3=5.2Mvar。同样,在其余点设置满足正态分布的随机干扰,检测结果如表4所示:
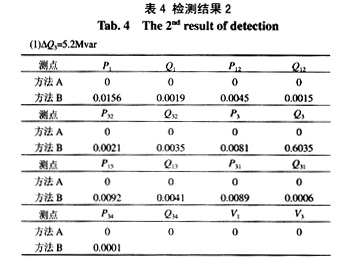
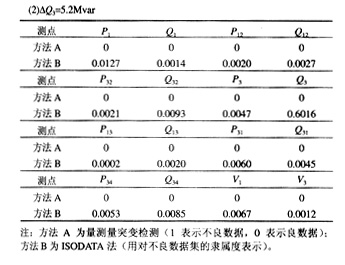
由以上结果可以看出,当P1和Q3点的不良数据值大小接近于量测量突变检测的门槛值时,量测量突变检测由于随机干扰的影响,2次检测得到了不同的结果。而ISODATA法采用隶属度概念来说明其属于不良数据的程度,保持了较高的准确性。
5 结论
&n [1] [2] 下一页
|





 网友评论:(只显示最新10条。评论内容只代表网友观点,与本站立场无关!)
网友评论:(只显示最新10条。评论内容只代表网友观点,与本站立场无关!)