����³���������
�Ϻ���ͨ��ѧ��������ϵ��200030 �Ϻ�
���������ҹ����õķ�չ����������ˮƽ����ߣ��Ե������������������Ե��ܵ�����Ҫ��Ҳ������ߡ����õ����ĸ���Ԥ�⣬�ǹ��粿�Ű�ȫ���ɿ�����;������еı�֤��
���������������ɷ�չ�ͱ仯������Ƚϸ��ӣ��ô�ͳ�ĸ���Ԥ�ⷽ���õ��Ľ�����ڸ��ɵĴ�С�͵����ֲ��϶������Žϴ��ƫ�Ϊ����Ӧʵ�ʵ���Ҫ��80�����H.L.Willis��1������˿ռ为��Ԥ������(spatial load forecasting theory)���÷��������ܹ�Ԥ��δ���ĸ������ı仯���ɣ����Ҷ�δ���ĸ��ɵ����ֲ����Ҳ��������Ӧ��Ԥ�⡣�˺�Mo��yuen Chow��2��4�������컪��5�����ռ为��Ԥ��Ӧ����ʵ�ʵij����滮�У�ȡ���˽Ϻõ�Ч����
����Ŀǰ������ר����ѧ�߽��ռ为��Ԥ����ص���ڶ�Ԥ��������δ������ʹ�������Ԥ���ϣ�������Ϊ���г��������ƵĹ�������ؽ������ɶȱȽϴ����ص�ʹ����Ҫ���г�������������Ԥ��ʱ���õ��������ɷֲ��Ĺ��ɣ�����Щ������Ԥ�����ص�ʹ��Ҳ�ȽϺ���������ijЩ��ʷ���أ����ڵ�����ʹ������Ƚϸ��ӣ������ؽ����д����Ž϶��������Ϊ�����ص�ʹ��һ���������������������滮���ؼ۳��ø��ߣ���������ȡ�����أ�������ʹ�þ���ʱ��Ҫ���ǻ��������Ӱ�졢��Ǩ�Ѷ��Լ���Ϊ���صȡ����ɿռ为��Ԥ��ʱ�����ǵļ�������(��ѧУ����·�������ĵľ��룬�μ����ף�2��5��)���Ѿ������ص�δ��ʹ���������ˣ��ڸ���Ԥ��ʱ��Ӧ�����������صĹ滮������Ϊ��Ҫ�����ݡ�
�����������ռ��������ݻ������о��˿ռ为��Ԥ�⣬�����ص���ڶԸ��ฺ�ɵĸ����ܶȵ�Ԥ���ϡ���ԭʼ���ݲ���ֵ������£�����ģ���㷨���˹���Ԫ�����еľ��������ȡ���������Ч����
1������ģ��
2.1���˹���Ԫ����������
����Ӧ���˹���Ԫ�����еľ�����ѧϰ(competitive learning)����ԭʼ���ݽ��о������(classification)����ͼ1��ʾ��ͼ�У�xi(i��1��2������n)������ʸ��x�ķ�����wij�Ƿ���xi����j����Ԫ��Ȩ�أ�Yj(j��1��2������m)�ǵ�j����Ԫ��������ھ�����ѧϰ�������У�ÿһʱ��ֻ��һ����Ԫ�����������֮Ϊʤ���ߡ�
���� ȡnki��wTix����(1)
���塰ʤ���ߡ�Ϊ
����Winner��wTix��wTjx������j��1,2,��,m����(2)
����ֻ��ʤ���ߵ�Ȩ�����ı䣬�������ʤ������һ�С�(Winner_Take_All)����Ȩ��w��������ʽ��
����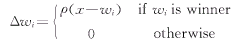 ����(3) ����(3)

ͼ1��������ѧϰ�Ļ�������
Fig.1��Interacting network of competitive learning
�������ף�7����֤����Ȩ��w1,��,wm��������XTX������ʸ����
������ͼ2���Կ�������ʼ��Ȩ��������ֲ��ģ��������ѧϰ֮��Ȩ�ر�ʾ�˸���ʸ������������
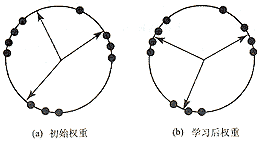
ͼ2��Ȩ�طֲ�
Fig.2��Weights distributing
2.2��ģ��������
�������ڿ�������������ȷ��ֵ��ʾ������������⣬ģ����ѧ����������ȵĸ�������ȿ̻�����������ijһ��������̶ȡ�һ�������������������������������������˹�������������������ȡ����IJ������������������������ȡ�
��������������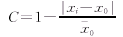 ����(4) ����(4)
ʽ�С�CΪ�����ȣ�xiΪ�Ա�����x0Ϊ����ֵ��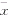 0Ϊ����ֵ�� 0Ϊ����ֵ��
2�������˹���Ԫ��ģ����ѧ�Ŀռ为��Ԥ��
�������Ȱ����ɵ����ʽ����ɷ�Ϊ�����ɡ���ҵ���ɡ���ҵ���ɡ�ũҵ���ɺ������ȼ��ࡣ
����Ȼ��Ѥ�������ֳ�����С�?��)��С��(��)������빩������ѹ�ȼ��йأ���ѹ�ȼ�Խ�ͣ�����С������ԽС��С��(��)һ��Ϊ��������״��1�����������Σ�����������߿ռ为��Ԥ�ⷽ����ͨ���ԡ��ӹ��粿�ŵĽǶȿ����������ڰ�Ԥ����������Ȼ�Ļ���Ϊ�Ľ���������С�飬����������ֵ��ȣ��Ա������ݵ��ռ��������������������㷨��ͨ���ԡ�
�����ռ为��Ԥ���Ի��ֺõ�С��(��)Ϊ������ÿһ��С��(��)�пռ为��Ԥ��Ĺ��̿�������ʽ����ʾ��
����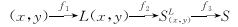 ����(5) ����(5)
ʽ�С�f1��ʾ��Ԥ����δ��������ʹ�������Ԥ����ฺ�ɷֲ���ӳ�䣻f2��ʾ�Ը��ฺ���ܶȺ���Ӧ���ɵ�Ԥ�⣻f3��ʾ���ܸ�����Ԥ����2����
2.1���ռ���С����δ�����ɷֲ�����
�������ڿռ为��Ԥ��Ҫ����������ܴ����ݵĴ���Ҳ�����ѣ��ռ为��Ԥ��һֱ����Ӧ����ʵ�ʡ�Ϊ�˿����˻��ڵ��ӵ�ͼ�����ݿ�ĵ�����Ϣϵͳ(GIS)�����������ԭʼ����֮�����Զ�ʵ�ָ������ݵ�ͳ�ƺʹ�����ʹ�ռ为��Ԥ���Ч�ʴ����ߡ�
������һ�����ڶ�����Ϊ(x,y)������ȷ�����ʵ�f1��ͨ���������滮�����ռ�����С�������ع滮�����������뵽GISϵͳ�����Եõ���Ԥ��С���ķֲ�����Ӧ����������õ�������Ҫ���f1��ÿһС�����ฺ�ɺ�������ص���ʷֵҲ���Դ�GISϵͳ�еõ���
������Щ�����������滮�У���С���õ�����û����ϸ�Ĺ滮��ֻ�����˴��µĻ��֣���ʱ���������ף�5���е����ۺ�������������ϸ�������ֲ����ݵIJ��㡣
2.2��С�����ฺ�ɵ��ܶȺ���ֵ����ȡ
������һ��ռ为��Ԥ���У��ڶ��������Ƚϼ�����Ԥ�����еĸ��ɲ�ȡһ�µĸ����ܶȣ��ٳ���������ɵõ�����ֵ������ʽ��
����������SL(x,y)��sL(x,y)��L(x,y)����(6)
ʽ�С�SL(x,y)Ϊij�ฺ�ɵĸ���ֵ��sL(x,y)Ϊij�ฺ�ɵĸ����ܶȣ�L(x,y)Ϊij�ฺ�ɵ������
����ʵ����ͬһ�ฺ��Ҳ���ںܶͬ�������ȡ��ͬ�ĸ����ܶ�ֵ�������ϴ����Ծ����õ�Ϊ���� �����õ�ĸ����ܶ��浱�ؾ����ƽ��������˿��ܶȲ�ͬ����ͬ�������ȷ�������ܶ�ֵʱ�����õ�һ���еõ��ĸ��ฺ�ɼ�������ص���ʷ���ݽ��о��������Ȼ��С���õع滮��ȡС�������ڵ�������أ�����ģ���㷨�Ƚϴ�������������������ݵ������ȣ����С�������ܶȣ�����С�����ฺ�ɷֲ�������Ϳɵõ���Ӧ�ĸ���ֵ��
����(1) �������
�����Ը��ฺ�ɽ��о���������Ծ���Ϊ������Ϊ�����ܶ����˿��ܶȡ��˾����롢�˾����������ص�Ѻ�ú���ѵ������йء�������ص�ѡ������������ľ�������������ڴ˻����϶������������ľ��ɽ���ʸ��Xi(i��1��2������)��ÿ��Xi��ʾԤ������ijһС����ɺ�������ص����������5������������4��Ϊ������أ��˿��ܶȡ��˾����롢�˾���������Ѷ�ú���ѵı�ֵ�����ʣ���5��Ϊ�����ܶȵ������ʡ�
����Ϊ�˵õ��������ص���������ʸ��Ҫ�Ƚ��й�һ��������ÿ��ʸ���ķ���ȡƽ��ֵ
����������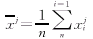 ����(7) ����(7)
�����任�����X�ķ���Ϊ
��������������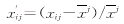 ����(8) ����(8)
����Ȼ��ÿ�����ѡ��һ��ʸ��������Ԫ���磬ʸ����һ��������Ӧ�����һ�������xj(j��1,2,��,5)�������õ��Ľ����ʤ���ߵ�Ȩ�أ�����һ����Ϊһ��ѧϰ��
���������־����
������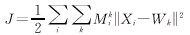 ����(9) ����(9)
 ������(10) ������(10)
�����������ѧϰ����J��ֵ���ټ�С��仯��Сʱ������Ԫ��Ȩ��Wj��������������XTX������ʸ��(X����ʸ��XiΪ��ʸ���ľ���)������һ���ķ����̣��Ϳɵõ�Xi�ķ��������
����(2) �����ȷ���
�������ɽ��з���֮���������ȵķ�����ȷ��δ�������õ��������������е���һ��?
���������þ�����������õ��ķ�����T1,T2,��,Ts,������ʸ������һ��֮��ΪXn��1,���и����ܶ������ʷ���Ϊ����Xn��1��T1,T2,��,Tn�������ȣ��ɵ�������ط�����������Pi,jΪ
����������pi,j��1����X(n��1),j��Ti,j��������(11)
������pi,j����Ȩ����Ӻ��ɵõ�Pi
��������������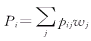 ������(12) ������(12)
����Ȩ�ص�ȡֵ���������صķ����йء��Ը������������֮����ƽ��ֵ���ɵõ�����������صı��d1��d2��d3��d4�����������Ȩ�أ�w1��w2��w3��w4��
��������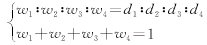 ����(13) ����(13)
����ȡPiֵ���ʱ��Ӧ��i����δ���ľ������ڵ�i�࣬����õ�i��ĸ����ܶ������ʺ�С��ԭ���ĸ����ܶ����δ���ĸ����ܶȡ�
��������֪����ijһ�������ݵ����Ƚϴ�������ʵ���С������ص�Ȩ�أ��Լ�С���Խ����Ӱ�졣�����ڴ�������ʱ�Եú��������ݾ��ȵ�Ӱ��Ҳ�Ƚ�С��
����(3) ����������
����ͨ�����ϵļ�����Է��֣���õ�Ԥ�⸺�������ʲ��ᳬ������ʷˮƽ������ʵ�����п��ܳ���ʷ����������˱����������������������ĵ����������Ǹ�����ʷ�����ʵ���������δ���ij�������
������δ���ĸ������ڵ�i�ࣺ
����1)��Ԥ����Ļ�������������ʸ��X(n��1)�͵�i�ฺ����Ӧʸ��Ti�л�������������֮���ƽ����E(I)��
��������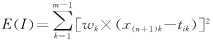 ����(14) ����(14)
ʽ�С�wkΪ��k���������ص�Ȩ�ء�
������E(I)��ֵ����һ������ֵʱ��Ҫ����������
����2)ͬ�������i��������ʸ��Xi��Xj��������������֮��ļ�Ȩƽ���ͣ�������G(L)
������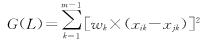 ������(15) ������(15)
��������ʽ����G(L)ʱ��Ӧ���������ܶ������ʷ�������Ӧ��G(L)����ʷ�����ʵĸ����ܶ�����
D(L)��xim��xjm����(16)
ʽ�С�xim��xjmΪ��i��j����ʷ���ݶ�Ӧ����ʷ�����ܶ������ʡ�
����3)����E(I)��G(L)֮��ľ���ֵA(I,L)��ȡA(I,L)��Сʱ��LΪL0��
������ ����(17) ����(17)
��������D(L0)Ϊδ���ij��������������δ���ĸ����ܶ�������Y��Ϊ
Y����Y��D(L0)����(18)
ʽ�С�Y��ti��mΪ���i��������Ӧ�ĸ����ܶ������ʡ�
�������������δ���ĸ����ܶ������ʿ��Եõ�δ���ĸ����ܶ�Den��
������������������Den��Den0��Y�䡡��(19)
ʽ�С�Den0Ϊԭ���ĸ����ܶȡ�
������Den������Ӧ�Ĺ������S��Ϳɵþ���Ԥ��ֵL
L��Den��S����(20)
2.3����С�����ܸ���
�����������ϼ���ɵõ�С�����ฺ��ֵ�������Ǽ������������ʵ���ͬʱ�ʾͿɵõ�С���ܸ��ɡ�
3������
������ijС���ľ���Ԥ��Ϊ���������е��㷨���м��顣����������13��������йص�ԭʼ���ݣ�ÿ�����ݰ����˿��ܶ������ȡ��˾����������ʡ��˾����������ʡ���Ѷ�ú���۸�֮�������ʺ����ܶ������ʡ������������1��ʾ��
��1��ԭʼ����
Tab.1��Raw data
��
��
�˿��ܶ���
����/%
�˾�������
����/%
�˾�������
����/%
��Ѷ�ú���۸�
֮��������/%
�����ܶ���
����/%
1
0.0320602
4.838514
10.3
1.016
13.81
2
0.0391689
5.059789
10.1
1.052
12.56
3
0.0358312
4.919944
9.9
1.117
11.22
4
0.0349338
2.881173
6.3
1.605
5.79
5
0.0310652
2.609315
6.2
1.592
4.52
6
0.0320268
2.325503
6.5
1.579
6.61
7
0.0589364
1.122041
5.3
1.677
5.15
8
0.0610925
1.351033
5.1
1.516
5.81
9
0.0635574
1.269853
5.4
1.772
5.83
10
0.0339299
[1] [2] ��һҳ
|





 ���������ۣ���ֻ��ʾ����10������������ֻ�������ѹ۵㣬�뱾վ�����أ���
���������ۣ���ֻ��ʾ����10������������ֻ�������ѹ۵㣬�뱾վ�����أ���